rlauxe
CLCA error rates
last updated Mar 19, 2025
Table of Contents
Estimating Error
The assumptions that one makes about the CLCA error rates greatly affect the sample size estimation. In an ideal world, these rates would be empirically determined, and public tables for different voting machines would be published. While these do not affect the reliabilty of the audit, they have a strong impact on the estimated sample sizes.
In a real-world measurement of a voting machine, one might measure:
- percent time a mark is seen when its not there
- percent time a mark is not seen when it is there
- percent time a mark is given to the wrong candidate
If the errors are from random processes, its possible that the 4 rates are approx the same, but also possible that some rates are more likely to be affected by errors than others. Its important to note that error rates combine machine errors with human errors of fetching and interpreting ballots.
We currently have two ways of setting estimated error rates. Following COBRA, the user can specify the “apriori” error rates for p1, p2, p3, p4. Otherwise, they can specify a “fuzz pct” (explained below), and the apriori error rates are derived from it.
In both cases, we use CORBRA’s adaptive estimate of the error rates that does a weighted average of the apriori and the actual error rate from previous samples. These estimates are used in COBRA’s OptimalLambda algorithm, which finds the optimal bet given the error rates.
This algorithm is used both when estimating the sample size, and also when doing the actual audit.
CLCA error rates
The CLCA error rates are:
p2o: rate of 2-vote overstatements; voted for loser, cvr has winner
p1o: rate of 1-vote overstatements; voted for other, cvr has winner
p1u: rate of 1-vote understatements; voted for winner, cvr has other
p2u: rate of 2-vote understatements; voted for winner, cvr has loser
For IRV, the corresponding descriptions of the errror rates are:
NEB two vote overstatement: cvr has winner as first pref (1), mvr has loser preceeding winner (0)
NEB one vote overstatement: cvr has winner as first pref (1), mvr has winner preceding loser, but not first (1/2)
NEB two vote understatement: cvr has loser preceeding winner(0), mvr has winner as first pref (1)
NEB one vote understatement: cvr has winner preceding loser, but not first (1/2), mvr has winner as first pref (1)
NEN two vote overstatement: cvr has winner as first pref among remaining (1), mvr has loser as first pref among remaining (0)
NEN one vote overstatement: cvr has winner as first pref among remaining (1), mvr has neither winner nor loser as first pref among remaining (1/2)
NEN two vote understatement: cvr has loser as first pref among remaining (0), mvr has winner as first pref among remaining (1)
NEN one vote understatement: cvr has neither winner nor loser as first pref among remaining (1/2), mvr has winner as first pref among remaining (1)
See Ballot Comparison using Betting Martingales for more details and plots of 2-way contests with varying p2error rates.
CLCA sample sizes with MVR fuzzing
We can estimate CLCA error rates as follows:
The MVRs are “fuzzed” by taking fuzzPct of the ballots and randomly changing the candidate that was voted for. When fuzzPct = 0.0, the cvrs and mvrs agree. When fuzzPct = 0.01, 1% of the contest’s votes were randomly changed, and so on.
In the folowing log-log plot, we plot CLCA sample size against the actual fuzz of the MVRs, down to a margin of .001, using the standard strategy of noerror (see below).
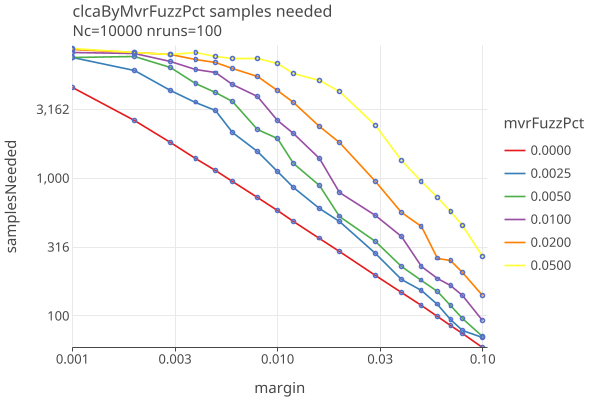
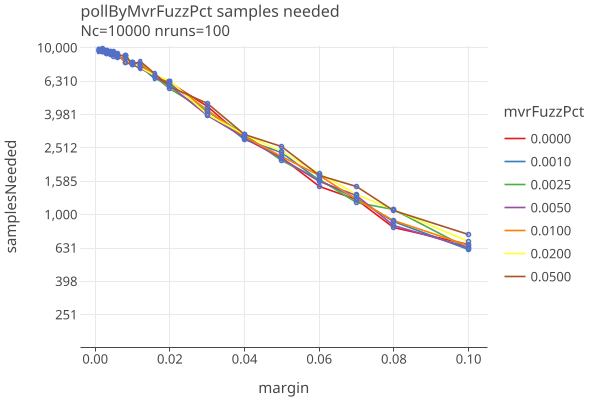
In contrast, the following log-linear plot for polling audits shows less sensitivity (and higher sample sizes):
CLCA error rate simulation with MVR fuzzing
We use fuzzed MBRs to generate CLCA error rates, as a function of number of candidates in the contest. Note that margin doesnt effect these values.
GenerateComparisonErrorTable.generateErrorTable()
N=100000 ntrials = 200
generated 1/26/2026
| ncand | r2o | r1o | r1u | r2u | |——-|——–|——–|——–|——–| | 2 | 0.2624 | 0.2625 | 0.2372 | 0.2370 | | 3 | 0.1401 | 0.3493 | 0.3168 | 0.1245 | | 4 | 0.1278 | 0.3913 | 0.3520 | 0.1158 | | 5 | 0.0693 | 0.3496 | 0.3077 | 0.0600 | | 6 | 0.0554 | 0.3399 | 0.2994 | 0.0473 | | 7 | 0.0335 | 0.2816 | 0.2398 | 0.0259 | | 8 | 0.0351 | 0.3031 | 0.2592 | 0.0281 | | 9 | 0.0309 | 0.3043 | 0.2586 | 0.0255 | | 10 | 0.0277 | 0.2947 | 0.2517 | 0.0226 |
Then p2o = fuzzPct * r2o, p1o = fuzzPct * r1o, p1u = fuzzPct * r1u, p2u = fuzzPct * r2u. For example, a two-candidate contest has significantly higher two-vote error rates (p2o/p2u), since its more likely to flip a vote between winner and loser, than switch a vote to/from other.
We give the user the option to specify a fuzzPct and use this table for the apriori error rates.
Calculate Error Rates from actual MVRs (oracle strategy)
One could do a CLCA audit with the actual, not estimated error rates. At each round, before you run the audit, compare the selected CVRs and the corresponding MVRs and count the number of errors for each of the four categories. Use those rates in the OptimalLambda algorithm
The benefit is that you immediately start your bets knowing what errors you’re going to see in that sample. That gives us a fixed lamda for that sample.
This algorithm violates the “predictable sequence in the sense that ηj may depend on X j−1 , but not on Xk for k ≥ j .” So we use this oracle strategy only for testing, to show the best possible sampling using the OptimalLambda algorithm.
CLCA sample sizes by strategy
These are plots of sample sizes for various error estimation strategies. In all cases, synthetic CVRs are generated with the given margin, and MVRs are fuzzed at the given fuzzPct. Except for the oracle strategy, the AdaptiveBetting betting function is used.
The error estimation strategies are:
- noerror : The apriori error rates are 0.
- fuzzPct: The apriori error rates are calculated from the true fuzzPct.
- 2*fuzzPct: The fuzzPct is overestimated by a factor of 2.
- fuzzPct/2: The fuzzPct is underestimated by a factor of 1/2.
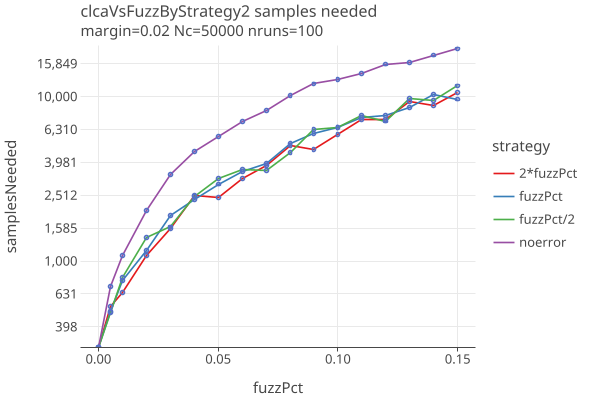
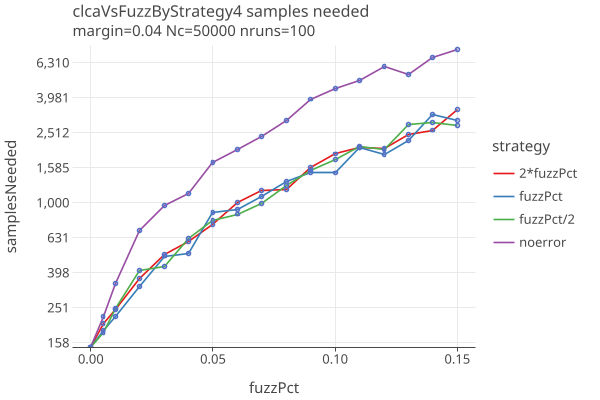
Here are plots of sample size as a function of fuzzPct, with a fixed margins of .02 and .04:
Notes:
- The noerror strategy is significantly worse in the presence of errors.
- If you can guess the fuzzPct to within a factor of 2, theres not much difference in sample sizes.